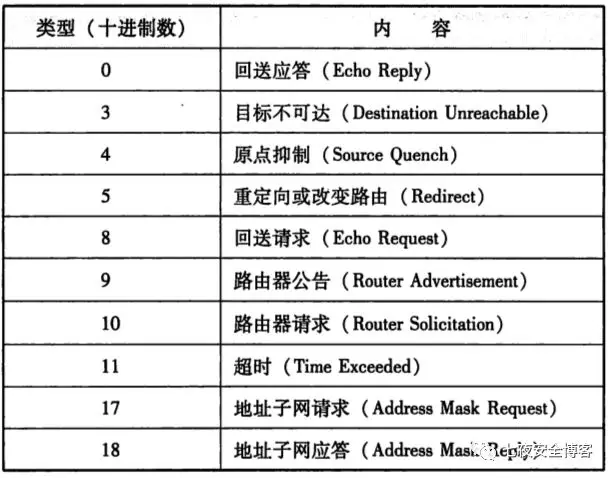
Python中struct.pack()和struct.unpack()用法详细说明
python 中的struct主要是用来处理C结构数据的,读入时先转换为Python的 字符串 类型,然后再转换为Python的结构化类型,比如元组(tuple)啥的~。一般输入的渠道来源于文件或者网络的二进制流
struct.pack()和struct.unpack()
在转化过程中,主要用到了一个格式化字符串(format strings),用来规定转化的方法和格式
struct.pack(fmt,v1,v2,.....)
将v1,v2等参数的值进行一层包装,包装的方法由fmt指定。被包装的参数必须严格符合fmt。最后返回一个包装后的字符串
struct.unpack(fmt,string)
顾名思义,解包。比如pack打包,然后就可以用unpack解包了。
返回一个由解包数据(string)得到的一个元组(tuple), 即使仅有一个数据也会被解包成元组。其中len(string) 必须等于 calcsize(fmt)
这里面涉及到了一个calcsize函数。struct.calcsize(fmt):这个就是用来计算fmt格式所描述的结构的大小
格式字符串(format string)由一个或多个格式字符(format characters)组成,对于这些格式字符的描述参照

示例代码
import struct # native byteorder buffer = struct.pack( "@ihh" , 1 , 2 , 3 ) print (repr ( buffer )) print (struct.unpack( "@ihh" , buffer )) # data from a sequence, network byteorder data = [ 1 , 2 , 3 ] buffer = struct.pack( "=ihh" , * data) print (repr ( buffer )) print (struct.unpack( "=ihh" , buffer )) data = [ 1 , 2 , 3 ] buffer = struct.pack( ">ihh" , * data) print (repr ( buffer )) print (struct.unpack( ">ihh" , buffer )) data = [ 1 , 2 , 3 ] buffer = struct.pack( "<ihh" , * data) print (repr ( buffer )) print (struct.unpack( "<ihh" , buffer ))
结果:
b'\x01\x00\x00\x00\x02\x00\x03\x00'
(1, 2, 3)
b'\x01\x00\x00\x00\x02\x00\x03\x00'
(1, 2, 3)
b'\x00\x00\x00\x01\x00\x02\x00\x03'
(1, 2, 3)
b'\x01\x00\x00\x00\x02\x00\x03\x00'
(1, 2, 3)
我的电脑默认是小端模式
在Format string 的首位,有一个可选字符来决定大端和小端
列表如下
大小端模式:
大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
通俗点说把存储结构当做列表,存储的单元是正序排列还是倒序排列的。
例如:
data = [ 1 , 2 , 3 ] buffer = struct.pack( ">iii" , * data) print (repr ( buffer )) print (struct.unpack( ">iii" , buffer )) data = [ 1 , 2 , 3 ] buffer = struct.pack( "<iii" , * data) print (repr ( buffer )) print (struct.unpack( "<iii" , buffer ))
结果:
b'\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x03'
(1, 2, 3)
b'\x01\x00\x00\x00\x02\x00\x00\x00\x03\x00\x00\x00'
(1, 2, 3)